
히터뷰 |
홍창범 엔젠바이오 소프트웨어 개발본부장
"시약과 SW 시너지, 엔젠바이오 NGS진단 원천"

"2014년 KT 재직할 때 부임한 황창규 회장이 회사 내부 NGS 사업부를 보고 가능성을 직감하며 '도와줄 것 없냐'는 질문을 했습니다. 우리는 '독립하고 싶어요'라고 답했죠"
차세대 염기서열 분석법(NGS) 전문기업 엔젠바이오(대표 최대출)의 시작은 KT 1호 사내벤처였다.
클라우드 기반 사업 아이템을 모색하던 중 발견한 유전체 데이터를 단순히 클라우드화하겠다고 나선 최대출 대표와 홍창범 SW본부장 등 당시 회사 내 연구진들은 NGS에 진단을 더한 새로운 플랫폼을 내놓겠다는 마음으로 KT의 울타리를 벗어났다.
엔젠바이오 소프트웨어 개발본부 홍창범 본부장은 사업 초기부터 10여년 간 갈고닦은 소프트웨어가 진단시약을 고도화 시키고 고도화된 진단시약을 통해 축적된 데이터가 다시 소프트웨어를 발전시키는 원천이라고 소개했다.

2010년 NGS 영역에 처음 발을 들이셨어요.
당시 KT는 클라우드 컴퓨터라는 시스템이 자리잡고 있던 상황이었습니다. 물리적 저장장치를 벗어난 클라우드 기반 사업을 물색하던 중 유전체 데이터 사업에서 가능성을 확인했습니다.
유전체 데이터 사업 가능성을 어떻게 판단했나요?
NGS에서 병목 현상이 발생하고 있다고 판단했습니다. 클라우드 플랫폼으로 풀어낼 수 있다고 생각했습니다. 사업 시작은 유전체 데이터 분석을 손쉽게 만들 클라우드 기반 플랫폼 구축이었습니다.
NGS 진단에 본격 진출하신 이유는요?
NGS 데이터 연구 시장이 국내에서 그다지 활발하지 않았습니다. 연구를 위한 NGS시장 공략을 위해서는 해외 진출을 추진하거나 다른 방안을 모색해야 했습니다. NGS 진단이라는 키워드를 만들어냈습니다. 회사 정체성으로 삼고 유방암을 타깃하는 진단시약과 소프트웨어를 만들기로 결정했습니다.
유방암을 첫 타깃으로 잡은 이유가 따로 있을까요?
NGS 진단을 사업 아이템으로 잡았던 당시에는 NGS 진단이 활발히 연구되던 시기는 아니었습니다. 기술이 고도화되지 않은 상황에서 BRCA1, BRCA2 유전체 두개로 진단이 가능한 유방암을 타깃으로 정했습니다. 이후 혈액암 등으로 영역을 넓혀왔습니다.
2013년 안젤리나 졸리는 유전자 검사에서 BRCA 유전자 변이를 확인했고 암 발병 가능성을 차단하기 위해 난소를 적출하고 유방을 절제하며, BRCA 및 유전자 검사에 대한 인지도가 단숨에 높아지기도 했습니다. NGS에 대한 진입장벽이 낮아질 수 있다는 점도 (유방암 진단 시장 진출의) 요소였습니다.
시작 단계 부터 소프트웨어가 포함된 만큼 중요한 위치를 차지해 왔을 것 같아요.
NGS 진단 핵심은 데이터 분석에 있습니다. 생산된 데이터를 분석해야 결과물이 탄생하기 때문입니다. 따라서 NGS 데이터 분석 기술은 KT시절부터 확보해 둔 상황이었죠.
진단으로 영역을 넓힐 수 있었던 것도 SW의 역할이 컸습니다. 엔젠애널리시스는 연구자용 NGS 플랫폼을 의료인용으로 전환하는 과정에서 탄생한 엔젠바이오만의 소프트웨어 'NGeneAnalySys'입니다.

의료인용 전환은 어떤 의미죠? 연구자용과 어떻게 다른가요?
유전체 변이가 있다면 여기에 대응할 수 있는 방안은 여러가지입니다. 같은 변이를 발견하더라도 어떤 이는 A라는 행동을, 어떤이는 B라는 행동을 취합니다.
이에 대한 어느정도 기준을 마련하고자 미국 의학유전학회에서는 ACMG라는 가이드를 제공했습니다. 어떠한 변이가 발견됐을 경우 해석할 수 있는 기준을 제시하겠다는 취지였습니다.
NGeneAnalySys는 연구용 가이드라인을 현장에 적용함과 동시에 부수적인 데이터를 담아 현장에서 확인될 수 있는 변이에 가장 적절한 대응을 제공합니다.
AI기반 소프트웨어라는 점에서 NGeneAnalySys가 NGS 분석에 대한 '로우앤드'를 올려 줄 수 있다고 생각하면 될까요?
일부 맞는 말입니다. 그렇지만 우리가 제공하는 기능 중 첫번째는 여러 툴(Tool)을 설정해 준다는 것이 있습니다.
툴은 무엇이죠?
NGS 분석은 여러 단계로 구분됩니다. 그런데 그 단계별로 어떤 툴을 사용할 것인가는 사용자가 결정해야 하는 사항입니다.
NGS 분석과정은 맵핑 - 베리언트 콜 - 인터프리테이션으로 구분되는데 이 각 과정에서 맵핑 단계에서는 어떤 툴을 사용할지, 베리언트콜은 어떤 방식으로 진행할지를 결정해야 하고 이를 수동으로 입력해야 했습니다.
또한 각 단계별로 나온 결과물을 다음 과정으로 옮기는 작업도 해야 하죠. 이 과정에서 휴먼에러 가능성이 생깁니다.
위양성 변이를 찾아내는 것도 NGS 데이터 분석에서 중요한 사항이라고 들었습니다.
파운데이션 메디슨이라는 미국회사에 한국 병원이 의뢰를 한 적이 있습니다. 그런데 실제와 잘못된 결과가 오는 사례가 많았어요. 원인을 찾아보니 한국인에게서는 높은 확률로 발견되는 변이였는데 서양인 기준으로는 아니었던 것입니다.
사용자 혹은 사용자의 분석 SW가 이 같은 특별한 부분들을 리스트화 해서 보관하고 있었더라면 발생하지 않았을 이슈였습니다. 이를 위양성이라고 한다면 위양성은 사용 장비, 시약 시험 인종 등 여러 요소들로 위양성 분석결과를 생산하기도 합니다. 저희는 데이터베이스를 기반으로 이 같은 블랙리스트를 정해 자체적 필터링이 가능합니다.
블랙리스트가 있다면 화이트리스트도 있나요?
변이 기준(threshold)을 화이트리스트라고 말 할 수 있습니다. 유전자 변이가 100점을 만족해야 특별한 케이스로서 소프트웨어가 분석-보고를 한다고 가정해 봅시다. 유방암 환자를 검사할 때 BRCA1,2 의 기준값을 100점에서 50점으로 낮춰 일반적으로는 다소 낮은 기준의 변이도 탐지하게 한다는 의미이기도 합니다.
한번에 백여 개 유전자가 동시에 시퀀싱 됐다고 가정했을 때, 쓰레스홀드 값이 모두 같다면 균등한 결과를 얻지 못합니다. 유전자 특성상 시퀀싱이 원활하지 않은 부위가 있기도 하고 기기나 시약이 갖고있는 특성을 반영할 수 있어야 한다는 것도 중요합니다.
기존 데이터에서 확인된 유전체 특성에 따라 블랙리스트와 화이트리스트를 만들어 변이와 위양성 변이를 찾는다는거죠?
그렇지만 그것만으로도 적절한 변이를 완벽하게 찾아내지 못하는 경우가 있습니다.
NGeneAnalySys는 추가적으로 다양한 정보를 제공합니다. 우리나라를 기준으로 보면 한국인에서 특정 변이가 얼마만큼 나타나는가에 대한 정보를 제공할 수 있습니다.
만일 한국인 10명 중 5~6명에게 확인되는 변이라면 특정 암과 상관관계를 추정하기는 무리가 있습니다. 이런 식으로 소프트웨어는 사용자가 특정 옵션을 설정해 필터링 할 수 있는 기능을 제공합니다. 위양성을 제거할 수 있는 필터링 옵션과 검출 변이의 중요도 평가가 소프트웨어가 갖는 특징입니다.

엔젠바이오 진단시약은 어떤 강점이 있나요?
NGS와 NGS 진단의 중요 포인트는 시약과 분석으로 구분할 수 있습니다. 유방암이라고 한다면 시약으로 조직 내 BRCA를 잡아낸 후 소프트웨어로 이를 분석하는 과정이 이뤄집니다.
시약과 분석은 검출 성능을 끌어내기 위한 요소로, 검출 성능은 어느정도까지 숨어있는 변이를 찾아내는가로 결정됩니다. 표를 보시면 암 조직을 가지고 시험을 하면 조직에는 암 조직과 정상 조직이 혼합돼 있습니다.
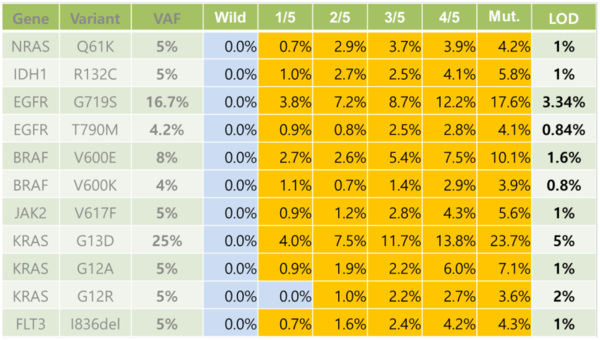
이는 얼마나 미세하게 존재하는 암 조직을 잡아낼 수 있는가가 성능을 가늠할 수있다는 의미입니다. LOD는 최소검출한계라는 정상조직 중 판별을 원하는 조직 비율입니다.
소프트웨어의 블랙리스트-화이트리스트처럼 시약도 중요시 하고있는 부분이 있나요?
일정하지 못한 커버리지를 만들지 않는 것이 중요합니다. 즉 백여개 유전체 데이터를 산출할 때 각 유전체 별 커버리지 곡선을 높은 수준에서 완만하게 만들어야 합니다. 쉽게 설명하면 우리는 시약에 유효한 데이터를 산출할 수 있는, 즉 유전체를 사로잡을 미끼를 설치합니다.
말씀드렸듯 어떤 유전자는 커버리지가 떨어져 데이터 생산이 다른 유전자 대비 적게 이뤄지기도 합니다. 포인트는 이 시약(미끼) 디자인입니다. 가령 어떤 미끼가 ACGCTT 염기서열을 잡아내기 위해 시약에 포함된다고 가정해보겠습니다.
그런데 염기서열 ACGCTT중 G부분이 특히 한국인에게 C라고 검출될 수 있다면 ACGCTT를 잡아내는 미끼가 ACCCTT를 잡아내지는 못합니다. 이러한 문제로 한국인에게는 유효한 데이터 생산이 되지 않습니다.
ACACAC 혹은 GCAGCA 같은 단순한 반복구조는 변이 검출이 쉽지 않습니다. 역시 데이터 생산이 원활하게 이뤄지지 않는 부분입니다. 이를 위해 ACGCTT-ACACAC 라는 배열이 돼 있다면 ACGCTT와 ACACAC를 검출할 수 있는 미끼들 사이에 CTTACA 를 검출할 수 있는 미끼를 걸어두는 것입니다. 이렇듯 부족할 수있는 영역 데이터 생산량을 끌어올릴 수 있는 비결은 시약에 있다고 할 수 있습니다.
변이 확인이 난해한 부분을 시약 고도화로 끌어내고 이를 분석한 결과 축적으로 SW고도화가 이뤄진다고 볼수 있겠네요.
네. 변이를 잘 찾아냈다고 해도 이 변이가 무엇을 의미하는지 설명할 수 없다면 의미가 없겠지요. 시약 고도화를 통한 분석 노하우는 소프트웨어에 스며들어 소프트웨어 데이터 축적과 리포트를 고도화 하고 이것이 다시 시약 개발 및 업그레이드로 이어집니다.
현재 저희는 △유방암&난소암 시약 'BRCAaccuTest® PLUS' △혈액암 시약 'HEMEaccuTest' HEMEaccuTest △고형암 시약 'SOLIDaccuTest' △희귀유전질환 시약 'HEREDaccuTest' △조직적합항원시약 'HLAaccuTest' 등을 보유하고 있는 상황입니다.
시약과 SW 고도화가 계속된다고 했을때, 이루고 싶은 목표는요?
NGeneAnalySys와 각종 시약을 통해 고도화된 데이터로 클라우드기반 사업을 본격화 하려고 합니다. 빅데이터화 시키고 AI가 바로 학습할 수 있는 플랫폼을 구축하고 업체들이 활용할 수 있는 사업화도 구상하고 있습니다. 화순 전남대병원과 용역계약도 연장선상에 있는 사업입니다.
화순전남대병원은 17만 건의 암 유전체 관련 데이터를 보유하고 있는데 이를 클라우드에 이식해 방대한 데이터를 토대로 산업에 활용할 수 있는 가능성을 모색하고자 합니다.